Кодирование текстовой информации
Вся информация, которую хранит, обрабатывает и передает по сетям компьютер, представлена в виде двоичных чисел. Существуют международные стандарты и методы кодирования текстовой, числовой, изобразительной, звуковой и видеоинформации. Знание основных кодовых таблиц очень важно для правильного чтения информации Интернета, электронной почты, текстовых документов в м.
Для кодирования букв и других символов, используемых в печатных документах, необходимо закрепить за каждым символом числовой номер – код.
В англоязычных странах используются 26 прописных и 26 строчных букв (A ... Z, a ... z), 9 знаков препинания (., : ! " ; ? ( ) ), пробел, 10 цифр, 5 знаков арифметических действий (+,-,*, /, ^) и специальные символы (№, %, _, #, $, &, >, <, |, \) – всего чуть больше 100 символов. Таким образом, для кодирования этих символов можно ограничиться 7-разрядным двоичным числом (от 0 до 1111111, в десятичной системе счисления – от 0 до 127).
Первой такой 7-разрядной кодовой таблицей была ASCII (American Standard Code for Information Interchange), опубликованная как стандарт в 1963 г. американской организацией по стандартизации American Standards Association (ASA), которая позднее стала именоваться ANSI (American National Standards Institute, поэтому данную кодовую таблицу называют также и ANSI). Таблица содержала 32 кода команд или управляющих символов (от 0 до 31), большая часть которых сегодня не используется, и 95 кодов (от 33 до 127) для различных знаков.
В последующем данная таблица ASCII была принята как стандарт ведущими международными организациями по стандартизации.
Первой такой 7-разрядной кодовой таблицей была ASCII (American Standard Code for Information Interchange), опубликованная как стандарт в 1963 г. американской организацией по стандартизации American Standards Association (ASA), которая позднее стала именоваться ANSI (American National Standards Institute, http://www.ansi.org/, поэтому данную кодовую таблицу называют также и ANSI). Таблица содержала 32 кода команд или управляющих символов (от 0 до 31), большая часть которых сегодня не используется, и 95 кодов (от 33 до 127) для различных знаков, достаточных для работы с английскими текстами, как показано на рисунке 1.1.
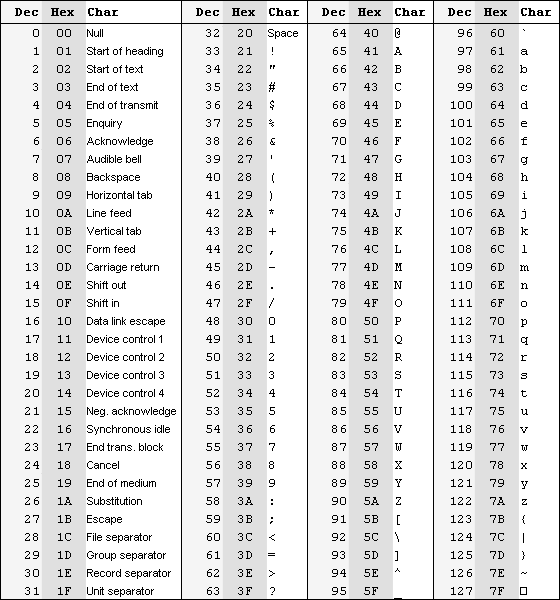
Рисунок 1.1
Однако для нашей страны и многих других стран необходимо было добавить в кодовую таблицу символы национальных алфавитов. Для этого было предложено использовать 8-битную кодовую таблицу, которая могла содержать дополнительно еще 128 символов (с 128 по 255).
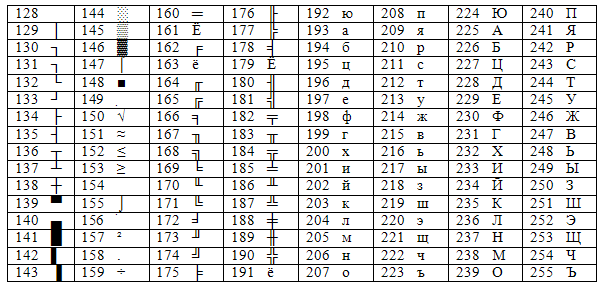
Рисунок 1.2
В дальнейшем был принят стандарт на 8-битную таблицу ASCII – ISO/IEC 8859, в которой первые 128 символов оставались те же, что и в 7битной таблице, а символы с 128 по 255 отводились для неанглийских символов.
Существует несколько частей этого стандарта:
- ISO/IEC 8859-1:1998 – Part 1: Latin alphabet No. 1,
- ISO/IEC 8859-5:1999 – Part 5: Latin/Cyrillic alphabet,
- ISO/IEC 8859-6:1999 – Part 6: Latin/Arabic alphabet,
- ISO/IEC 8859-7:2003 – Part 7: Latin/Greek alphabet,
- ISO/IEC 8859-8:1999 – Part 8: Latin/Hebrew alphabet и т. д.
Первые русские ЭВМ использовали 7-битную кодировку символов КОИ-7, в которой присутствовали прописные латинские буквы, а на месте строчных латинских были русские прописные буквы (кириллица).
Позднее на первых отечественных персональных компьютерах использовалась так называемая «Основная кодировка ВЦ Академии Наук СССР», в руководствах к старым матричным принтерам обозначаемая просто как «ГОСТ» – 8-битная кодовая таблица, вторая половина которой содержала символы псевдографики, русские прописные и строчные буквы.
В дальнейшем основной кодировкой русских букв для первой операционной системы ПК – MS DOS стала «Альтернативная кодировка ВЦ Академии Наук СССР» (вторая половина таблицы для кодов 128-255 приведена на рисунке 1.5). Содержит псевдографику (позволяющую в текстовом режиме рисовать рамки из одинарных и двойных линий). Существует несколько модификаций, отличающихся символами в последних 14 позициях. Зарегистрирована в IANA (Internet Assigned Numbers Authority – организация, отвечающая за административное управление в Internet) как IBM866 или CP866.
С широким распространением операционной системы Microsoft Windows и появлением ее национальных локализаций для второй половины таблицы ASCII было введено понятие «кодовая страница» (code page, CP).
В операционной системе Linux для представления русских букв используется кодировка КОИ-8R (рисунок 1.7), зарегистрированная в IANA как KOI8-R.
Кириллица Macintosh (компьютеров фирмы Apple), она же CP10007, довольно близка к CP1251. Не зарегистрирована в IANA, но часто обозначается как x-mac-cyrillic.
В 1991 году в Калифорнии была создана некоммерческая организация Unicode Consortium, в которую входят представители многих компьютерных фирм (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect и др.), и которая занимается развитием и внедрением стандарта «The Unicode Standard».
Стандарт кодирования символов Unicode становится доминирующим в интернациональных программных многоязычных средах. Microsoft Windows NT и его потомки Windows 2000, 2003, XP, Vista используют Unicode, точнее UTF-16, как внутреннее представление текста. UNIXподобные операционные системы типа Linux, BSD и Mac OS X приняли Unicode (UTF-8), как основное представления многоязычного текста.
Unicode резервируют 1114112 (220+216) символов кода, в настоящее время используются более 96000 символов. Первые 256 кодов символов точно соответствуют таковым ISO 8859-1, наиболее популярной 8разрядной таблицы символов «западного мира»; в результате, первые 128 символов также идентичны таблице ASCII.
В то же время, подобно двоичным файлам, кодировка Unicode мало подходит для непосредственной передачи по сети – байты в тексте вполне могут приходиться на область управляющих символов, поэтому обычно применяются две другие основанные на Unicode кодировки переменной длины, обозначаемые как UTF (Unicode Transformation Format): 7битная UTF-7 (последний пересмотр – RFC2152, 1997 г., зарегистрирована в IANA как UTF-7) и 8-битная UTF-8 (RFC2279, 1998 г., зарегистрирована в IANA как UTF-8). Обе они в каком-то смысле уже не являются языковыми кодировками, а являются программно распознаваемым кодом относительно исходного Unicode, но зарегистрированы они именно как кодировки, наравне с ISO 8859-5 или KOI8-R. Естественно, обе они не являются специфически «русскими», а пригодны для написания «сколько угодно»язычного письма.
В UTF-8 все символы разделены на несколько групп по значению первых битов. Символы с кодами менее 12810 кодируются одним байтом, первый битом которого равен нулю, а последующие 7 бит в точности соответствуют 128 символам 7-й таблицы ASCII (см. таблицу 1.2), следующие 1920 символов – двумя байтами (Greek, Cyrillic, Coptic, Armenian, Hebrew и Arabic символы). Последующие символы кодируются тремя и четырьмя байтами.
Таблица 1.2. Принцип кодирования символов в UTF-8
| Диапазон кодов (hexadecimal) | UTF-8 (binary) | Notes |
| 000000 00007F | 0xxxxxxx | Первый бит 0, следующие 7 соответствуют таблице ASCII |
| 000080 0007FF | 110xxxxx 10xxxxxx | Первые 3 бита 110 – всего используется 2 байта, второй байт начинается с 10 |
| 000800 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx | Первые 4 бита 1110 – всего используется 3 байта, второй и третий байты начинаются с 10 |
| 010000 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | Первые 5 бит 11110 – всего используется 4 байта, второй, третий и четвертый байты начинаются с 10 |
Таким образом, в настоящее время при работе в Интернете Вы можете встретить следующие кодировки для кириллицы:
- CP1251 – Cyrillic Windows – операционной системы Microsoft Windows;
- CP866 – Cyrillic DOS – операционной системы MS DOS;
- ISO 8859-5 – Cyrillic ISO – 8-ми битная таблица ASCII ;
- KOI8-R – операционной системы Linux;
- CP10007 – операционной системы компьютеров Macintosh;
- UTF-8 – универсальная Unicode кодировка переменной длины.
| Понятие информации, ее виды и свойства | Кодирование числовой информации |