Как устроен индекс поисковой машины
Индекс — слово, которое постоянно упоминается в связи с поисковыми машинами. Увы, большинство пользователей Интернета до сих пор смутно представляют, что это такое. Хотя, как мы уже говорили выше, ничего сложного в этом понятии нет. Более того, ему много веков, и каждый из нас встречался с индексом в виде предметного указателя книги еще до своего первого выхода в Интернет.
Давайте рассмотрим процесс индексирования текста подробнее и разберемся с устройством индекса. Вот какие шаги выполняет поисковая машина для создания индекса из выкачанных веб-страниц.
Конверсия в чистый текст
Для начала текст индексируемой страницы нужно очистить от всяких нетекстовых элементов: графики, разметки (тегов) языка HTML, прочего «мусора». В результате получается чистый текст, с которым дальше работает индексный робот.
Выборка слов
Из текста нужно выбрать все слова, чтобы затем расположить их по алфавиту. Для этого поисковик должен знать, что именно считается словом — последовательность букв (и какого именно алфавита), числа, буквенно-цифровые последовательности, слова с дефисом и т. п., а также что словом не считается и пропускается (пробелы, знаки препинания и прочее). Ниже мы расскажем об этом чуть подробнее. А сейчас лишь заметим, что у каждого поисковика есть свое определение того, что считать словом в тексте (стандарта здесь, увы, не существует).
Итак, поисковик выбирает из текста все, что считается словами, и собирает их в отдельный список.
Лингвистическая обработка
В большинстве поисковых машин слова не заносятся в индекс в том виде, в котором они приведены в тексте.
Обычно на этапе выборки слов из текстов веб-страниц поисковая машина применяет какой-то свой алгоритм лингвистической обработки слов, а именно, приведения слов к их начальным грамматическим формам, или основам (грубо говоря, к именительному падежу). Этот алгоритм называется машинной морфологией. Делается это для экономии места в индексе и, что еще важнее, для более точного поиска.
По поводу использования машинной морфологии в поисковиках также бытует довольно много мифов и домыслов, так что ниже, в отдельном разделе, мы специально коснемся этого вопроса. Пока же достаточно сказать, что машинная морфология служит для замены слов на их основы в индексе поисковика.
Составление индекса
Собранные вместе основы всех слов из всех текстов сводятся в индекс — своеобразный словарь, в котором основы упорядочены по алфавиту, а при каждой основе записано, с какой страницы она взята (номер страницы) и на каком месте на этой странице данная основа стояла (номер вхождения). Основы в словаре упорядочиваются по алфавиту для удобства поиска по ним.
Таким образом, индексная запись имеет следующую структуру:
ОСНОВА /номер страницы + номер вхождения / номер страницы + номер вхождения / номер страницы + номер вхождения / ...Конечно, в реальности для экономии места и повышения скорости использования индекса его структуру всячески оптимизируют и усложняют. Например, вместо основ в индексе хранят их номера (так как они короче и имеют фиксированную длину), а основы хранят отдельно; номера страниц пишут не всякий раз, а только единожды для всех вхождений с данной страницы и т. д. Затем индекс упаковывают для экономии места, еще раз индексируют для ускорения доступа и т. д.
Но общая идея индексной записи именно такова, как описано выше.
«Координатный» индекс
Первые интернет-поисковики (середины 1990-х годов) не запоминали местоположение слова на странице. В индекс записывался только список страниц, на которых встретилось данное слово. Это делалось для экономии места и для того, чтобы упростить структуру индекса, другими словами, для более быстрого доступа к индексу.
Однако это ограничение не позволяло достаточно точно определить релевантность страницы при поиске словосочетаний. Ведь поисковик не мог различить компактное вхождение слов запроса, когда они стоят рядом, в одной фразе, от разнесенного вхождения, когда одно слово запроса, скажем, находится в правом верхнем углу страницы, а второе — в левом нижнем.
В результате для многословных запросов релевантность была практически нулевой. Так, например, был устроен поисковик «Рамблера» вплоть до 1999 года.
С ростом числа многословных запросов (а их доля все время увеличивается по мере роста числа опытных пользователей) и по мере развития поисковых технологий большинство популярных поисковиков перешли на индекс, учитывающий координаты слова на странице. Такой индекс называется координатным.
Учет компактных вхождений слов запроса в координатном индексе позволяет не только более аккуратно «взвешивать» релевантность страницы, но и показывать наиболее подходящую цитату из текста страницы.
Как видим, индекс представляет собой обращенную, «вывернутую наизнанку» копию всех страниц Интернета. Если в обычном тексте мы идем от страницы к словам, то в индексе поисковая машина идет от слов к страницам. Поэтому индекс поисковой машины называется инвертированным или инверсным, то есть обращенным, перевернутым.
А откуда же берется цитата в поисковых результатах? Ведь в инвертированном индексе порядка слов в тексте явно нет. Неужели поисковик восстанавливает текст страницы по этому «вывернутому наизнанку» индексу?
Нет, хотя это технически и возможно. Для показа цитат гораздо проще и экономнее хранить еще и второй индекс, так называемый прямой, который по сути представляет собой сжатую текстовую копию всего Интернета.
Подробнее почитать о поисковых роботах, узнать, какие их виды бывают, а также посмотреть, как выглядит страница сайта, хранящаяся в прямом индексе, вы можете в разделе «Роботы поисковых систем» Приложения к этому курсу.
«Прямой» индекс
Чтобы показывать при найденных страницах цитаты с выделенными (подсвеченными) словами запроса, поисковые машины хранят все тексты всех проиндексированных страниц. Получается, что поисковики хранят у себя на серверах копию всего Интернета, выкачанного ее индексным «пауком». Например, Google имеет у себя текстовую копию всего мирового Интернета (в том объеме, до какого смог добраться его «паук»), а «Яндекс» — копию всего Рунета.
Для хранения текстовой копии страниц инверсный индекс не подходит — слишком долго каждый раз при отображении цитаты восстанавливать порядок слов в тексте. Гораздо проще хранить второй индекс, на жаргоне разработчиков называемый прямым. Он представляет собой тексты веб-страниц, очищенные от всех нетекстовых элементов, сжатые и упакованные, и является текстовой копией всего Интернета.
Именно наличие этой текстовой копии позволяет поисковым машинам не только показывать релевантные цитаты в результатах поиска, но и иметь функцию «восстановить текст страницы», которой удобно пользоваться, если сама нужная страница в данный момент недоступна или вообще уже удалена с сайта. В результатах поиска Google такая ссылка называется «Сохраненная копия», а у «Яндекса» — просто «Копия»). Иногда эта копия также называется «кэш страницы».
Пример
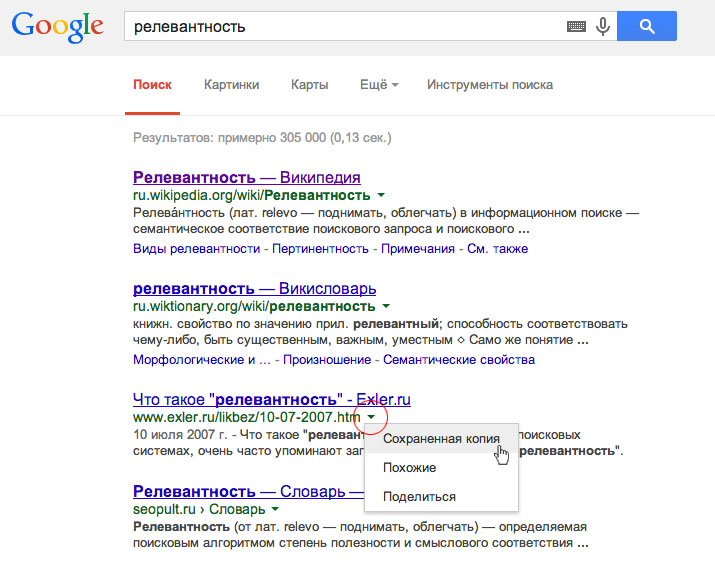
Нажав на ссылку “Сохраненная копия”, вы откроете веб-страницу в том виде, в котором она была проиндексирована в последний раз поисковой системой.
Пример
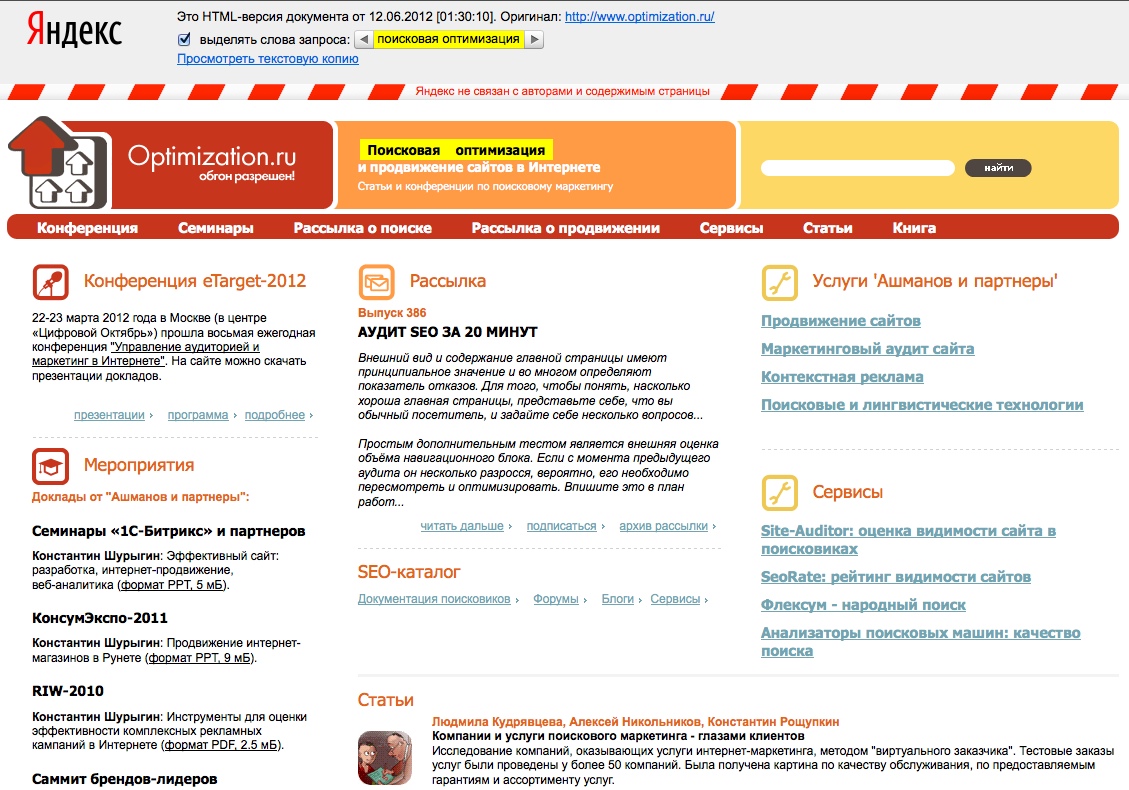
Так выглядит сохраненная «Яндексом» копия страницы сайта optimizatJon.ru, найденная по запросу «поисковая оптимизация». Как видим, «Яндекс» сохранил в своем «прямом» индексе не только текст, но и html-код страницы
До недавнего времени большинство поисковых машин хранили копию страниц без HTML-разметки, графики и прочего «мусора», в чисто текстовом виде. Однако, по мере развития IT-технологий почти все поисковые сервисы перешли на сохранение полной копии страницы, которую можно посмотреть в любой момент даже со всеми картинками, в том дизайне и в том оформлении, в каком она была на сайте во время скачивания поисковым роботом.
| Как работает поисковая машина | Какие слова индексирует поисковая машина |